-
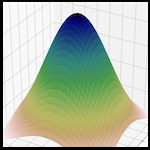
SumOfGaussians layer with Keras 2.0
Recently, the TensorFlow team announced their public 2.0 beta API
and I thought that would make a perfect excuse to see what has changed (and
plenty should have changed from the 1.x API…). …
-

Use Keras Pretrained Models With Tensorflow
In my last post (the Simpsons Detector) I’ve
used Keras as my deep-learning package to train and run CNN models. Since Keras is just
an API on top of TensorFlow I wanted to play with the underlying layer and therefore implemented
image-style-transfer
with TF. …
-

Simpsons Detector
When life gives you GCP credits, make a Simpsons Detector! …
-

Pickling Keras Models
It’s pretty annoying that Keras doesn’t support Pickle to serialize its objects (Models). Yes, the Model structure is serializable (
keras.models.model_from_json) and so are the weights (model.get_weights), and we can always use the built-inkeras.models.save_modelto store it as an hdf5 file, but all these won’t help when we want to store another object that references the model (likekeras.callbacks.History), or use the%storemagic of iPython notebook. …
-

Efficient Range-Joins With Spark 2.0
If you’ve ever worked with Spark on any kind of time-series analysis, you probably got to the point where you need to join two DataFrames based on time difference between timestamp fields. …
-

Cheapest Single-Node Docker Cluster
If you have 20$-30$/month and you’re willing to pay it for a server that you can run some stuff on, stop reading now and launch a
t2.smallor ag1-smallmachine. But if you’re a cheap bastard like me, and want to go even lower than the 4.68$/month that at2.nanomachine would cost - keep reading… …
-

Generating Random Polygons
Let’s generate random non-overlapping polygons on a plane! Sounded fairly simple to me at the beginning, but soon I discovered those nasty polygons are not as innocent as I thought. …
-

The Griddlers Ninja new serverless AWS architecture
Or - OMG! My AWS free-tier is over in 2 months and there’s no way I’m paying monthly fees for almost idle machines! …
-

Looking for the state of TLV - IL elections part #1
The “state of TLV” is a widely used phrase in Israel. Ask the average Israeli and he’ll tell you that everyone in TLV are left wing voters and we all eat sushi all day. That, of course, is far from the truth, but gives an opportunity to look at this theory from a more mathematical approach. …
-

Use Ruby Gems With Hadoop Streaming
For some data processing we do at work, I wanted to use Hadoop Streaming to run through a file with my ruby mapper code. I’ve used ruby and Hadoop Streaming in the past, but normally just for simple scripts that didn’t require anything but the standard packages that come with every installation of ruby. …

zachmoshe.com
Technical Consultant for Risk Management, Fraud Prevention and Data Science
About me
"Computers are useless. They can only give you answers." (Pablo Picasso, 1960s)